The Product
What it does
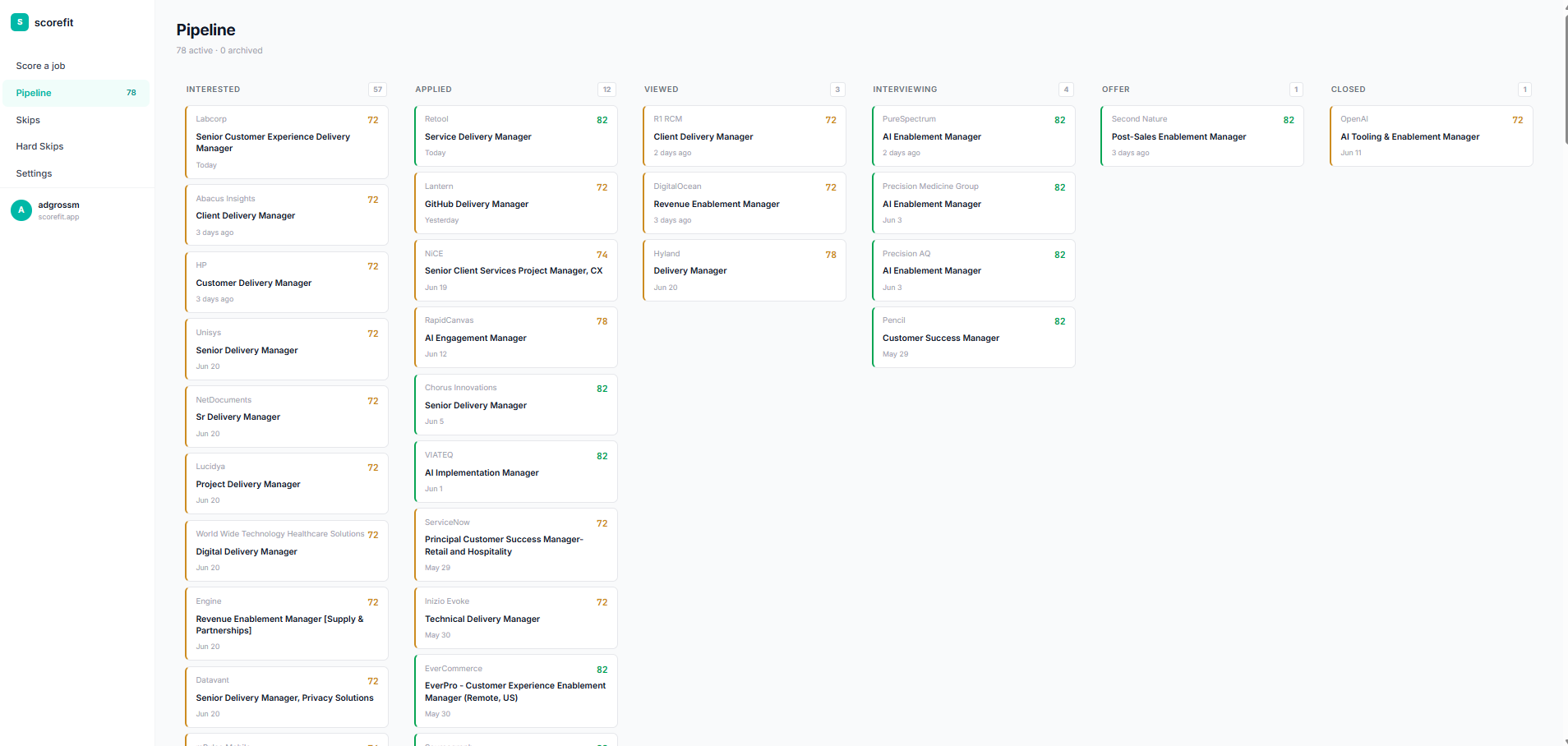
Employed professionals don't have time to read hundreds of listings to find the few worth pursuing. Existing tools either spray applications indiscriminately or bury the user in an unfiltered feed.
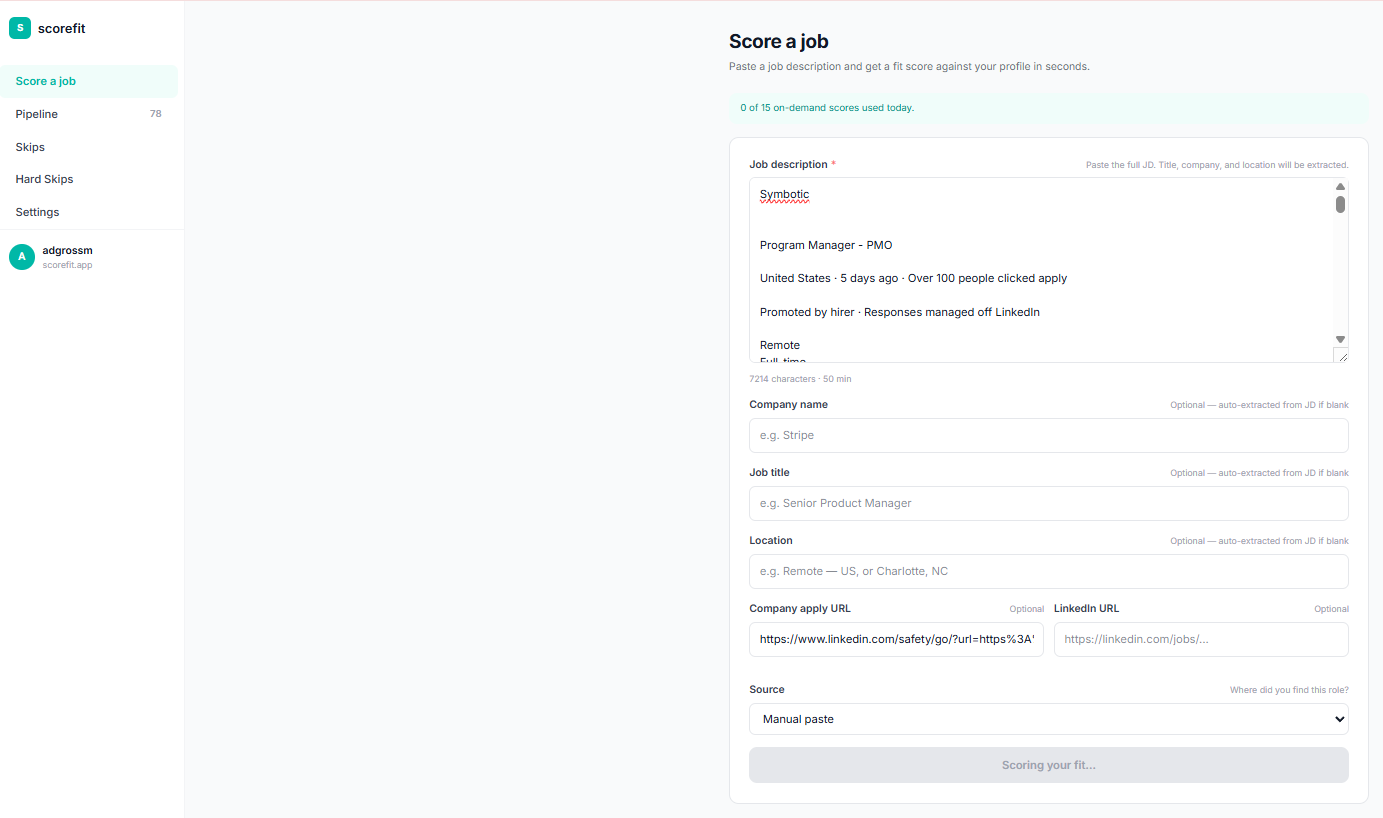
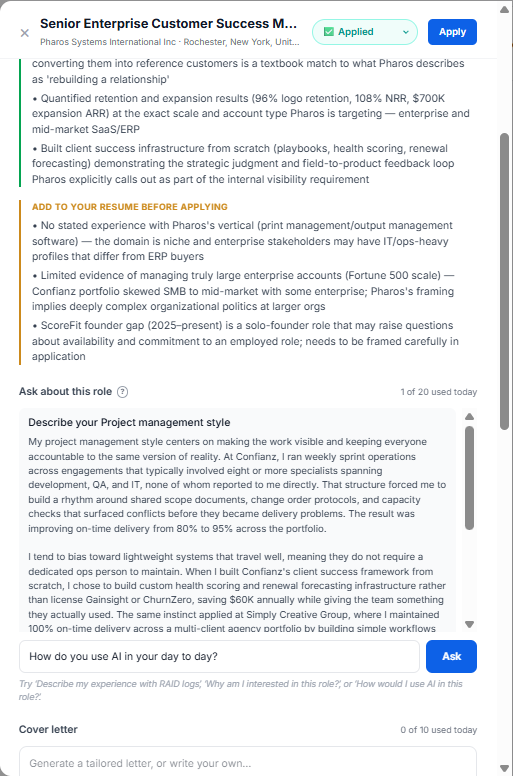
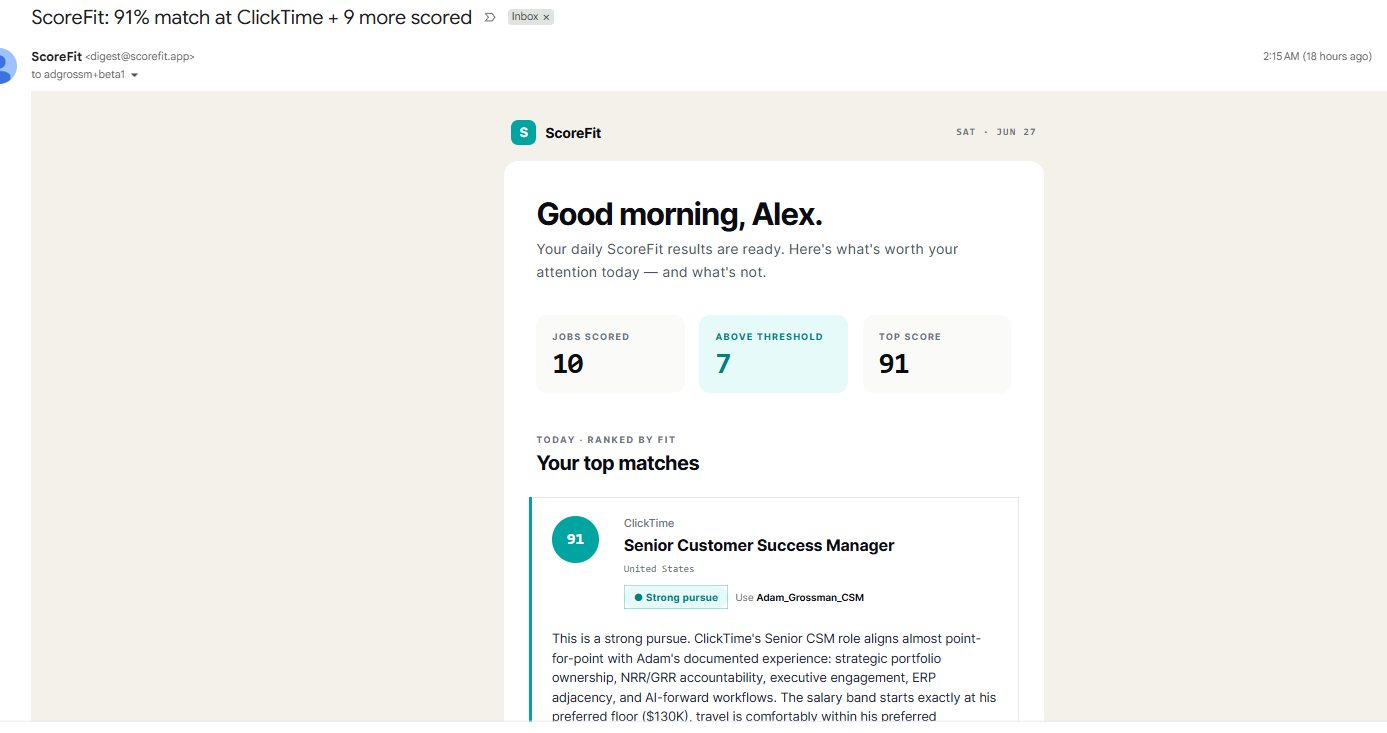
ScoreFit casts a wide net, scores sharply against the individual's real background, and lets the person decide. It recommends which resume version to use, tracks the application pipeline, and surfaces the roles worth pursuing -- without automating the decision itself.